Recent comments in /f/deeplearning
one_eyed_sphinx OP t1_j7tzoiq wrote
Reply to comment by suflaj in what cpu and mother board is best for Dual RTX 4090? by one_eyed_sphinx
>eco
so this is the fine point that I want to understand, what I am trying to optimize with the build is the data transfer time, how much time it takes to load a model from RAM to VRAM. if I have10 models that need 16 GB of VRAM to run, the need to share resources. so I want to "memory hot swap" (I don't know if there is a proper term for it, I found "Bin packing") the models on an incoming request. so the data transfer is somewhat critical in my point of view and as I understand it, only the PCI speed is the bottleneck here, correct me if I'm wrong.
ThomasBudd93 t1_j7teaca wrote
Last time I checked there were problems with running on training job on two or more RTX 4090s. Did these problems solve out? There were some posts in the pytorch and NVIDIA forums.
OSeady t1_j7so2j2 wrote
Just go AMD and get the fastest cpu your budget allows.
suflaj t1_j7s57dy wrote
At the moment a 7950X in eco mode combined with a ROG Strix X670E seems to be the best combo.
It running in 8x mode on PCI-E gen 4 doesn't really matter, according to benchmarks the performance difference is a few %. It will take a lot of time in 16x because it's pretty much the same speed. It will not get significantly faster with a different mobo, you're limited by the GPU itself, not the interface.
nutpeabutter t1_j7rxvb8 wrote
Reply to comment by DMLearn in Is there any AI-distinguishing models? by Such_Share8197
Your argument falls apart when you realize that there are training artifacts. Ever wonder why FID scales inversely with model size?
DMLearn t1_j7pq8wc wrote
Reply to comment by nutpeabutter in Is there any AI-distinguishing models? by Such_Share8197
The model is trained by getting rewarded for fooling a model that tries to distinguish between the real and fake images. So no, it won’t be perfect, but it’s going to be good enough to trick a model the vast majority of the time because that is literally a part of the training. Not just a small part, that’s is the central tenet of the training and optimization of generative models, generative ADVERSARIAL networks.
thelibrarian101 t1_j7p27ns wrote
Reply to comment by levand in Is there any AI-distinguishing models? by Such_Share8197
To add to this, openai itself is pretty mediocre at detecting AI generated text: https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text/
nutpeabutter t1_j7os2xj wrote
Reply to comment by levand in Is there any AI-distinguishing models? by Such_Share8197
Just because it can imitate doesn't mean it can do so perfectly.
Vegetable-Skill-9700 OP t1_j7omfxw wrote
Reply to comment by grigorij-dataplicity in Launching my first-ever open-source project and it might make your ChatGPT answers better by Vegetable-Skill-9700
Working on it :)
Such_Share8197 OP t1_j7o6crv wrote
Reply to comment by levand in Is there any AI-distinguishing models? by Such_Share8197
oh i see thanks for the reply!
levand t1_j7o5zeb wrote
Reply to Is there any AI-distinguishing models? by Such_Share8197
This is inherently a super hard problem, because (to oversimplify) the loss function of any AI generating NN is to minimize the difference between a human generated and AI generated images. So the state of the art for detection & generation is always going to be pretty close.
[deleted] t1_j7o580e wrote
johnGettings OP t1_j7lqkj2 wrote
Reply to comment by GufyTheLire in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
Yes, definitely agree. The project started as one thing, then turned into another, then another. I was only doing the coin grading for fun and wasn't planning on actually implementing it anywhere. So I switched gears and just focused on building a high resolution ResNet, regardless of what would be best for the actual coin grading.
There are probably better solutions, especially for this size of a dataset, and maybe a sliding window is necessary to achieve very high accuracy.
But I think this model can still be useful and preferable for some datasets of large images with fine patterns. Or at the very least preferred for simplicitys sake.
GufyTheLire t1_j7ljbmj wrote
Do you expect the model to learn subtle details useful for classification from a relatively small training dataset? Wouldn't it be a better approach to train a defect detector for the model to know what is important on your images and then classify found features? Maybe this is the reason why large classification models are not widely used?
thelibrarian101 t1_j7l4oi8 wrote
Reply to comment by johnGettings in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
Haha ok, I was hoping for a neat preset or sth ^^
johnGettings OP t1_j7l45fw wrote
Reply to comment by thelibrarian101 in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
Excel lol
thelibrarian101 t1_j7l3y43 wrote
What tool did you use to create these images? https://raw.githubusercontent.com/johnGettings/Hi-ResNet/main/images/HiResNet.png
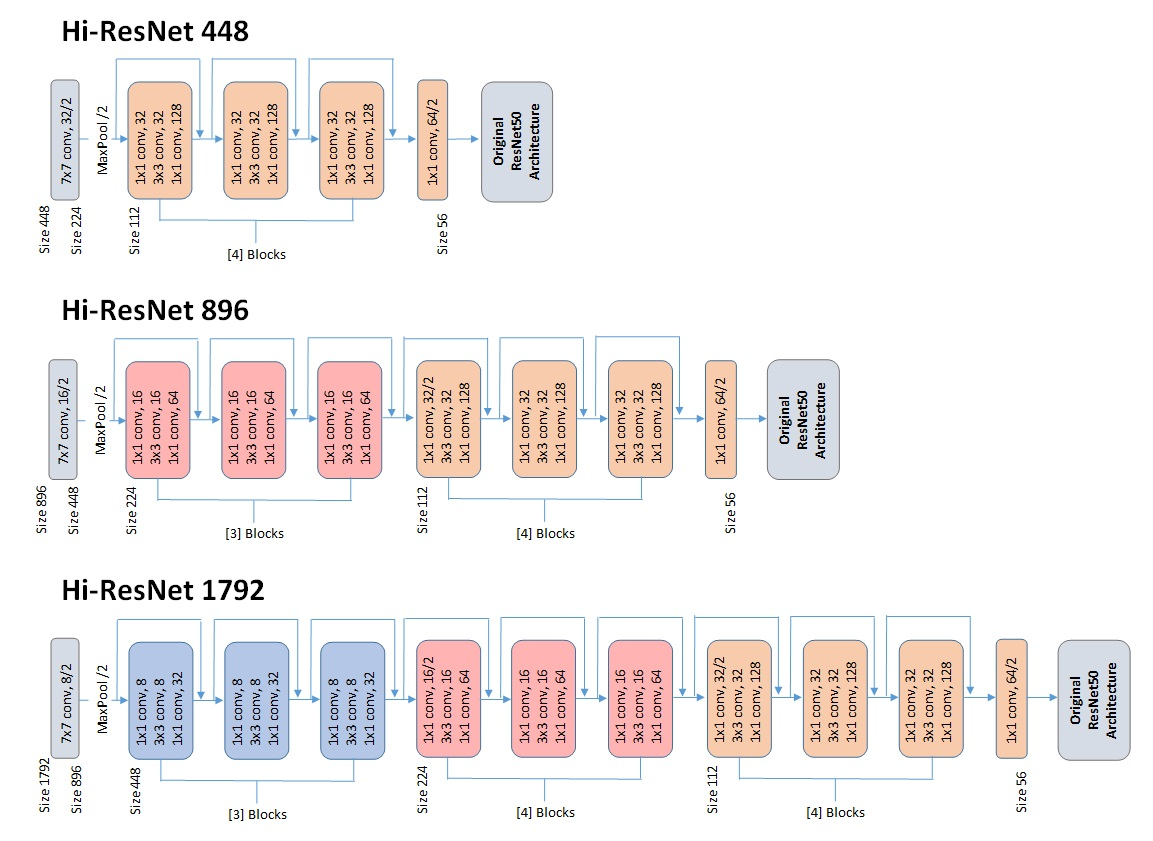{kind=link}
They look really good
just_phone_user t1_j7jytqc wrote
Reply to comment by johnGettings in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
How does your extended ResNet compares to a standard one with Global Average Pooling (like it's done in timm in PyTorch)?
beautyofdeduction OP t1_j7jqohn wrote
Reply to comment by neuralbeans in Why does my Transformer blow GPU memory? by beautyofdeduction
I wish I can send you my Github. But the original Attention is All You Need paper trained on sequences of length 25000 on multiple K80's (stated by the authors), which has only 12GB vram. Yes they used multiple GPUs, but afaik each GPU needs to be able to handle its own batch. Or maybe not? Again I wish I could show you my code.
neuralbeans t1_j7jdiqz wrote
Reply to comment by beautyofdeduction in Why does my Transformer blow GPU memory? by beautyofdeduction
A sequence length of 6250 is massive! It's not just 6250*6250 since you're not multiplying one float per pair of sequence items. You're multiplying the key and value vectors together per pair of sequence items, and this is done for every attention head (in parallel). I think you're seriously under estimating the problem.
What transformer is this which accepts a sequence length of 6250?
johnGettings OP t1_j7hwa3w wrote
Reply to comment by jimtoberfest in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
I didn't try it. I decided to just bust this out and move on to the next project. It was fun though.
jimtoberfest t1_j7huuug wrote
Reply to comment by johnGettings in Hi-ResNet: High resolution image classifier. (448, 896, 1792 sq.px.) by johnGettings
How did the tiling approach work out or you didn’t try it?
I had something similar in trying to identify spin on a baseball in successive frames.
beautyofdeduction OP t1_j7hkq74 wrote
Reply to comment by BellyDancerUrgot in Why does my Transformer blow GPU memory? by beautyofdeduction
That context of how much memory other models use up is helpful. Thanks for taking the time to respond.
beautyofdeduction OP t1_j7hkb7q wrote
Reply to comment by neuralbeans in Why does my Transformer blow GPU memory? by beautyofdeduction
Yes, that's true. But even adding that in (6250*6250 ~= 40 mil floats), we are still nowhere near 40G.
one_eyed_sphinx OP t1_j7tzqmj wrote
Reply to comment by ThomasBudd93 in what cpu and mother board is best for Dual RTX 4090? by one_eyed_sphinx
can you find me a reference?